


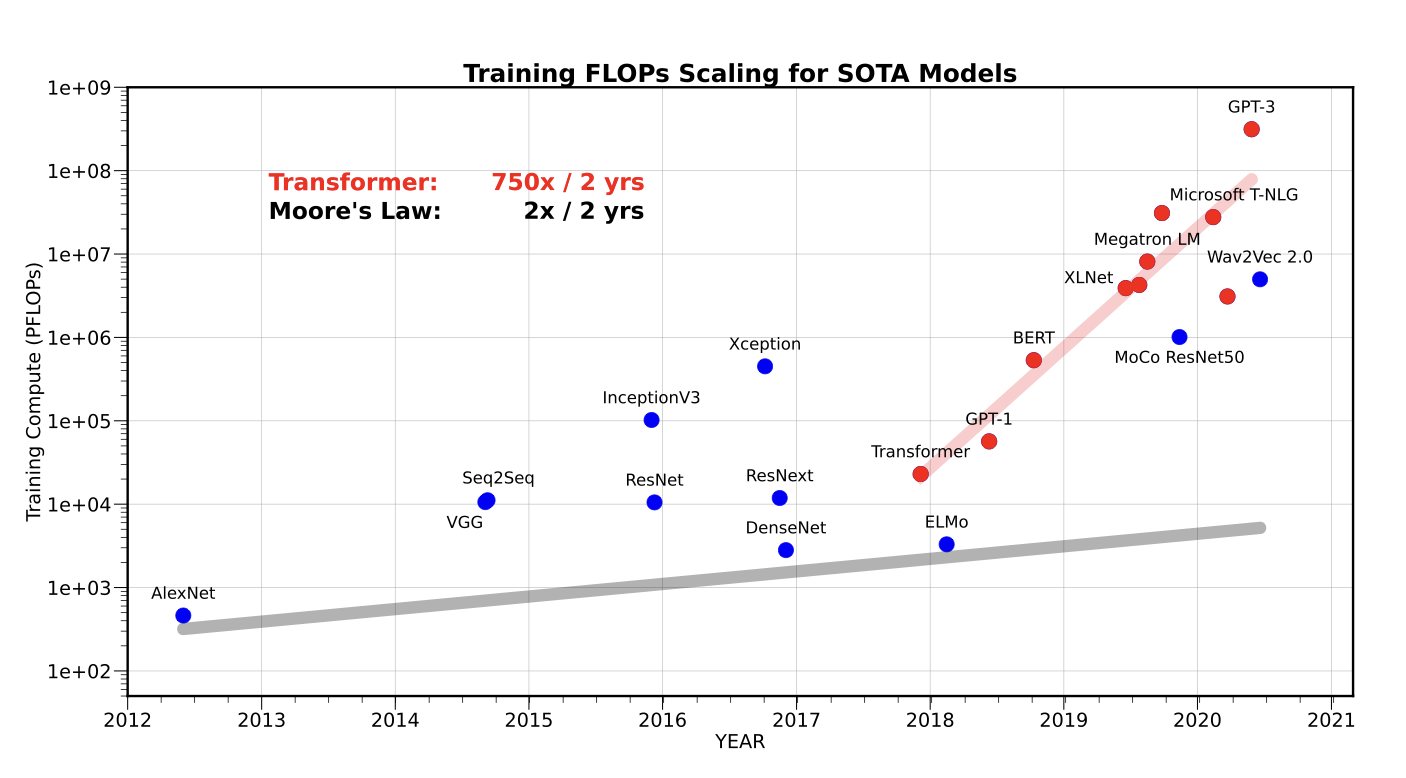
The rise of data centers in recent years is directly attributed to the need for a large number of GPUs for training AI models mostly based on the transformer architecture. When you train a LLM, it requires millions of GPU hours across thousands of accelerators (specialized hardware for AI training) implying thousands of GPUs in a data center running for days or weeks. We’ve seen the number of FLOPs (Floating point operations) necessary for training SOTA (state of the art) models like GPT-3 increase by 750x every two years.
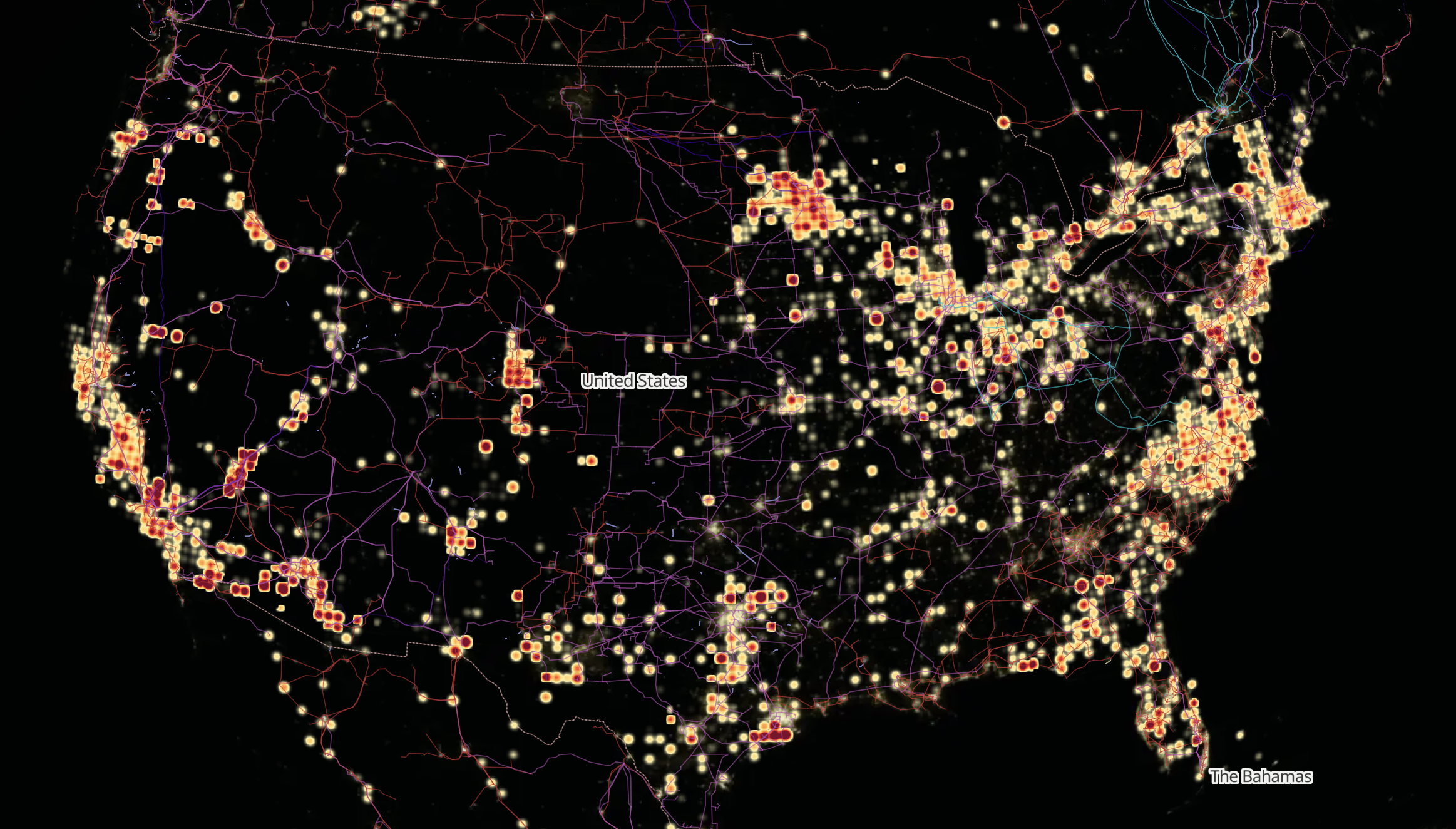
Data centers are measured in watts because they are fundamentally power systems: every server, GPU, network switch, and cooling unit consumes electrical power. Traditional single data centers are 50-300 MW, but next generation training clusters require 1-5+ GW of power. This power cannot be sourced from one site only, it has to be distributed across sites in the US to handle the incredible load.
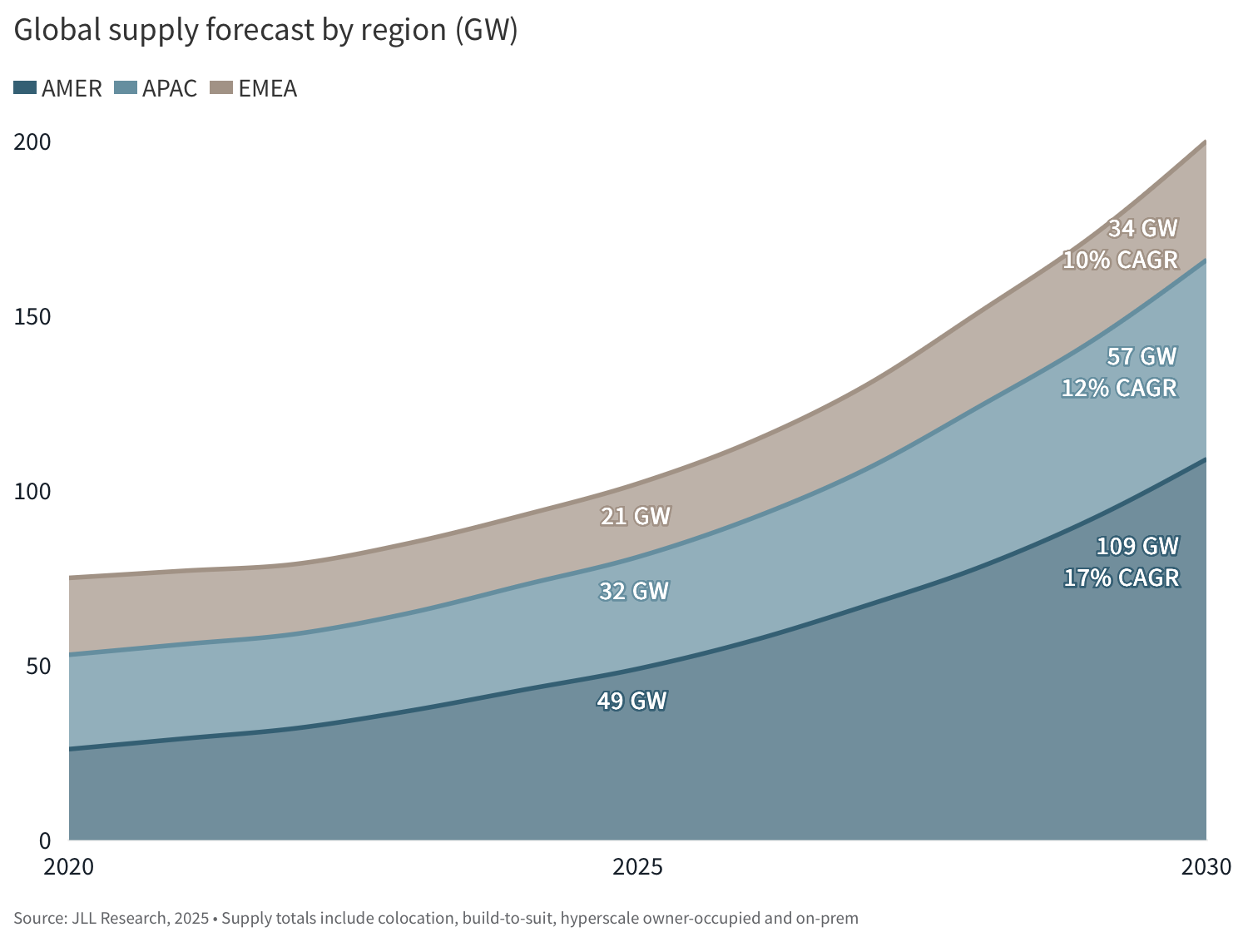
Industry forecasts show global construction spending reaching roughly $280 billion in 2026 alone, with total infrastructure investment entering a multi-trillion-dollar cycle through the end of the decade. Capacity is expanding at a pace rarely seen in physical infrastructure, with tens of gigawatts of new power coming online annually and meaningful additions already expected within the next year as part of a broader near-doubling of global capacity by 2030.
The choice for data center developers to build for training vs inference lends to consider many different tradeoffs.
You can share a data center, but training and inference compete for resources in ways that reduce performance and efficiency. At scale, it’s better to separate or strongly isolate them to avoid contention in scheduling, networking, and hardware utilization.
Inference data centers are optimized for continuous, scalable, revenue-generating workloads and tend to deliver better long-term ROI due to higher utilization, flexibility, and alignment with real-world demand. They have to be positioned closer to the usage sites for lower latency in real time applications.
There’s a huge demand for training data centers right now because of the increasingly large scale of SOTA AI models. Because training data centers are optimized for peak performance and synchronization, they are expensive and episodic.
Scaling AI systems is increasingly constrained by network performance, not just compute specifically. Collective operations turn distributed training into a network-bound problem, because they require large, synchronized, many-to-many data exchanges at every step (e.g model parallelism, sharing data, sharing weights across all GPUs). Latency becomes a key issue when you’re waiting for the GPUs to receive data or during inference when you’re measure TTFT (Time to First Token: the loading time to receive the first token response from the model). Finally, network jitter can affect operations when one link has delays even on the micro-second scale.
Hyperscalers like Amazon, Microsoft, and Google don’t actually build most of their data centers themselves. They act more like system designers and operators, then outsource execution to a pretty tight ecosystem of contractors. You’ll typically see large general contractors like Turner Construction or DPR Construction running the build, with specialized MEP (mechanical, electrical, plumbing) players handling the parts that actually matter, including power, cooling, and commissioning. What’s interesting is how dominant Irish firms have become in that layer. Companies like Jones Engineering, Kirby Group Engineering, and Mercury Engineering show up everywhere in hyperscale builds. A lot of that traces back to Ireland being an early European hub for cloud, so these teams got really good at mission-critical infrastructure early and then scaled with the hyperscalers globally. Today they’re often the ones actually delivering the hardest parts of these facilities, especially around high-voltage systems and cooling, while the hyperscalers focus on the compute layer and operations.

To put this massive shift in perspective, US AI data centers will need around “20 to 30 gigawatts (GW) of combined power by late 2027”. 30 GW is about 5% of US average current power generation capacity.
While some companies will attempt to reach power targets through single facilities, much of the industry believes in tying together several data centers into campuses to reach necessary capacity- DCI (Data Center Interconnect). Meta for example has been leveraging short range optics to connect data centers up to 10km+. Now, companies are starting to leverage LR optics, DWDM, and pluggable transceivers to further expand into larger clusters.
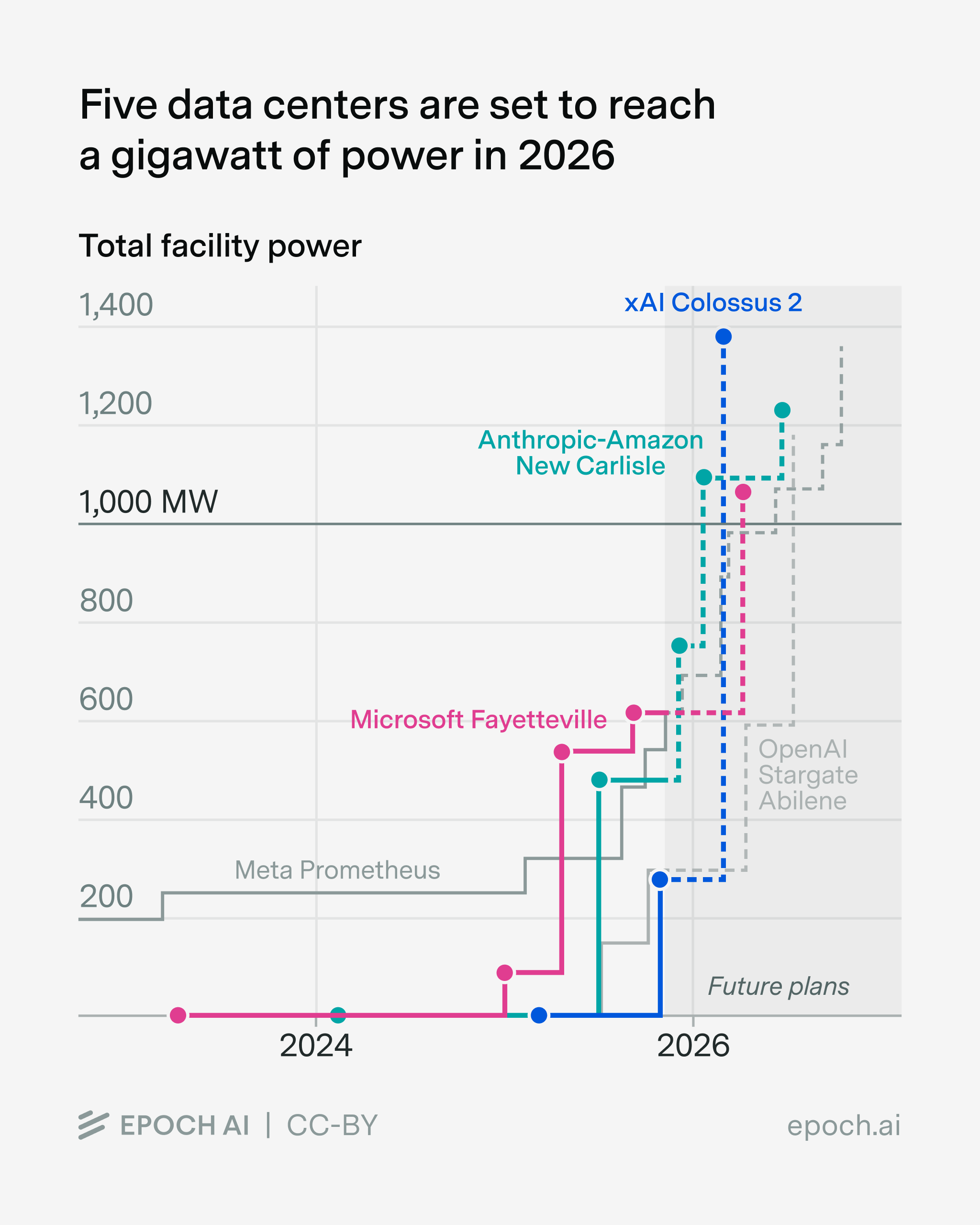
The largest bottleneck to data center development and growth is undoubtably the access to sufficient energy to power these massive facilities. Regulatory timelines typically take 3-7 years for new sites. The only exception thus far has been the XAI Colossus facility which was brought online in just 122 days. To achieve this the team utilized high voltage natural gas turbines and several hacked together solutions before the grid was able to support their operations.

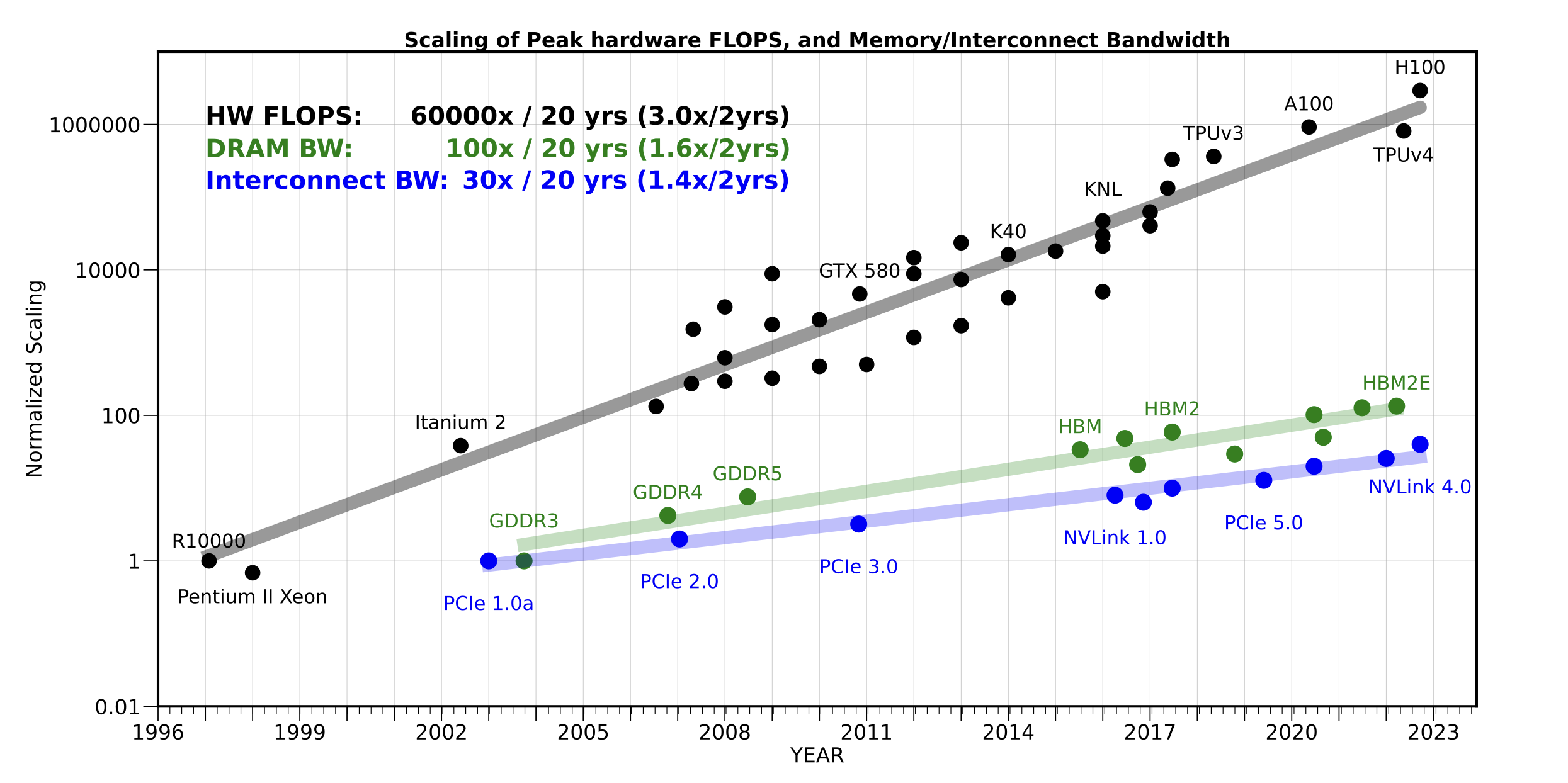
The second biggest constraint has been high bandwidth connectivity. The rate of development of connectivity interfaces like NVLink by NVIDIA has lagged behind the scaling of hardware flops in GPUs by three orders of magnitude as depicted in the figure below. Despite innovations in cables, PCIe (Peripheral Component Interconnect Express), hollow core optics, and more, connectivity. These limitations matter because it impacts the ability to chain data centers together across the country to form GW clusters.
Unfortunately, these two bottlenecks are also connected in that data transfer methods also require power. There is a tradeoff between distance (reach) and energy efficiency: Long-distance systems (e.g., telecom DWDM, Dense Wavelength Division Multiplexing) is great for 1000km plus but is >1000 pJ/bit whereas short-distance systems (inside data centers) are 1–10 pJ/bit (e.g LPO Linear Pluggable Optics). To put it in perspective, for a hyperscaler datacenter you could hit tens of thousands of watts just for data transmission - often taking up 10%-30% of a data center’s entire power consumption.
One of the largest bottlenecks to expansion is the need for large quantities of technicians and maintenance engineers onsite. Companies like Meta have even begun educational programs to try and rapidly train a generation of skilled laborers. Each large data center campus can require hundreds of technicians across rotating shifts, vendors, and support crews, with a single hyperscale region employing thousands of workers dedicated to ongoing maintenance alone. These technicians handle a constant stream of repetitive, hands-on tasks: swapping failed servers and drives, managing cabling, inspecting cooling systems, servicing power infrastructure, and responding to alarms 24/7. As operators build out gigawatt-scale clusters composed of multiple large facilities, the maintenance burden scales linearly with deployed hardware, creating a massive and continuously growing workforce requirement.

This becomes a critical constraint as new data centers are increasingly sited in remote areas to access power and land, where the local supply of skilled labor is limited. The result is a structural bottleneck: even with sufficient capital and energy, the ability to hire, train, and retain large numbers of qualified maintenance technicians is emerging as one of the primary factors limiting how fast new data center capacity can be deployed and reliably operated.
In many ways, the data center is the perfect environment for wheeled humanoid robots: flat terrain, strong wireless networking, controlled environmental conditions, and a huge unfulfilled demand for tiring repetitive tasks. Many hyperscaler data centers are over one million sq ft requiring that maintenance technicians waste time and energy walking miles each day.
At Yondu we train industrial wheeled humanoid robots to help automate repetitive, manual tasks across verticals. We create a real world data flywheel by remotely operating robots while performing repetitive value added tasks. We then use that data to train our robot foundation model to do that same task fully autonomously.
We can’t solve every problem, but we can help tackle one of the biggest bottlenecks to data center deployments nationwide - labor shortage. By first enabling technicians to multiply their impact and control multiple wheeled humanoid robots in the data center, we increase efficiency and save costs by allowing one person to do the job of multiple. Over time, as we collect data of tasks being done across data centers, we can train our foundation model to perform those same tasks fully autonomously with a simple command.

.png)